Best Practices
Best Practices
The process of naming a file or a folder is something that often receives little thought, but it is important for ease of access and discovery. A number of file naming conventions exist, and have been outlined below.
File Directories
People often nest folders within folders within folders as a primary organizational practice, but this can make discovery difficult, particularly for people who are new to the organization. Best practice is to have fewer folder levels, ideally no more than 3-5, and rely on information-rich file names for ease of access. If acronyms, codes, or abbreviations are used recurrently in file names, you may include a readme.txt file to describe their meanings.

Save the file as "00README.txt" - the 00 will keep it visible at the top of the folder.
Image Names
There are a few critical ground rules. Failing all else, these are the most important aspects of file naming best practices.
First: Do not use special characters. The only two exceptions are "_" and "-". Characters other than underscore or dash can cause read errors because they may have a functional role within certain programs or browsers.
Second: Do not use spaces. Spaces must be encoded by programs or browsers, and this can lead to read errors.
Third: Use leading zeroes when numbering files in sequential order. This means you have to think about a reasonable upper limit number for the files you're ordering. In some cases, a resume perhaps, maybe one leading zero may be sufficient (01, 02 ... 10, 12). In many other situations, like weekly reports or model runs, two, or even three, leading zeroes may be necessary (001, 002 ... 010, 011 ... 100, 101).
Typically, file names should start with more general components, such as date or event type, and move to specifics, such as version number. The files should be named in the most appropriate way to retrieve the record. To determine this, consider how your organization works and how people in your organization will think of the document when they go to retrieve it. Organizing by date first is standard recommended practice, and ensures that your data will be chronologically ordered. Date-first naming practices also help limit the possibility of accidentally overwriting data. However, meaningful descriptors may also be used to order files.
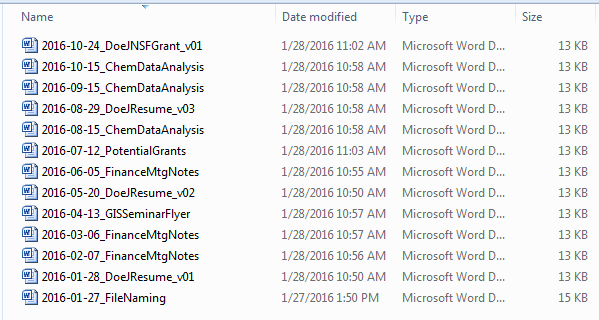
These files are ordered by date-first naming, which puts them in chronological order.
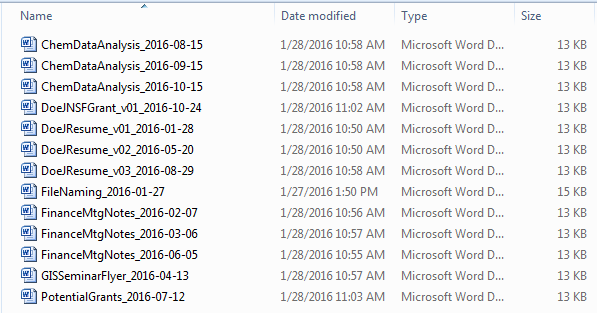
You can see how different organizations may prefer one of these methods over the other. Importantly, both methods use the same detailed information in the file names to maintain a high level of description. As seen above, file names should use back-to-front date formatting (Year-Month-Day) to ensure chronological organization. File names should also be as short as possible, avoiding filler words such as "the", "a", and "and". Long file names can become unwieldy and put unnecessary strain on a system, so 25 characters is the target maximum length for a file name. Meaningful abbreviations may be used to help keep file names short. In the above examples, chemistry is abbreviated to chem and meeting is abbreviated to mtg. As illustrated above, capitalized acronyms such as NSF should remain capitalized in file names. Whatever abbreviations you use, be consistent and ensure that everyone in the organization will be familiar with them. If uncommon abbreviations are used, be sure to identify them in the readme.txt file addressed above.
File names should be understandable, descriptive, and unique. In addition to limiting the potential for accidentally overwriting important content, good names will be clear about the file content. Depending on the needs of your organization, file names may include content such as: project title or experiment name (perhaps abbreviated), location, researcher name or initials (Note: use first name/last name convention: DoeJ, DoeJohn, DJ, etc...), or version number of the file (Note: when providing version numbers, avoid ambiguous terms like revision, final, or draft. Instead, use specific version indicators such as v001, v002, v1_0, v1_2, or v1a, v1b)
Remember that the more visually clear your file names are, the easier finding the file you want will be. There are a number of ways to structure your file names. These are:
Separation with dashes:
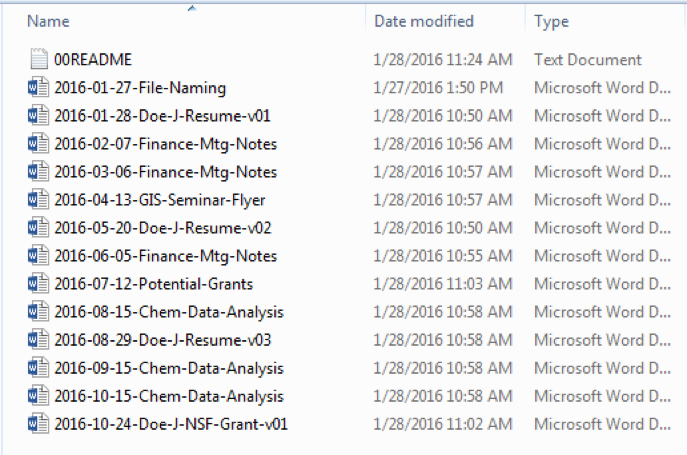
Here each item in the file name is separated by a dash.
Separation with underscores:
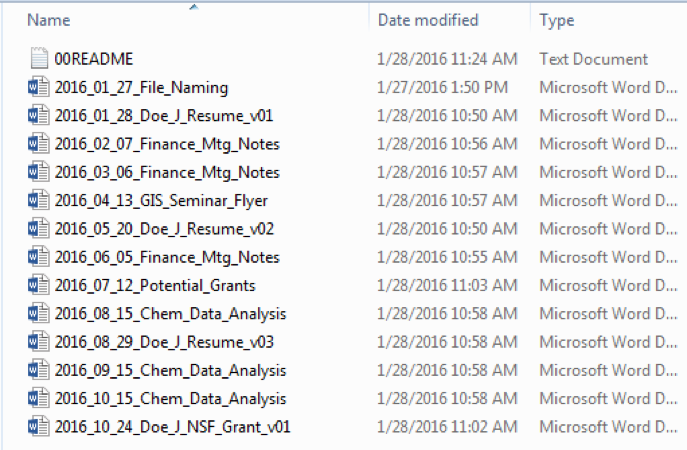
Here each item in the file name is separated by an underscore.
No separation:
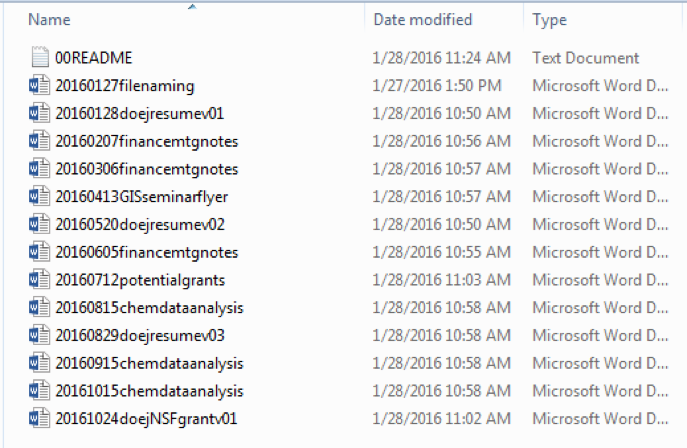
Here there is no spacing between items in the file name. It is not visually appealing, but it does cut down on character counts, which may be a higher priority depending on the needs of your organization.
Camel case:
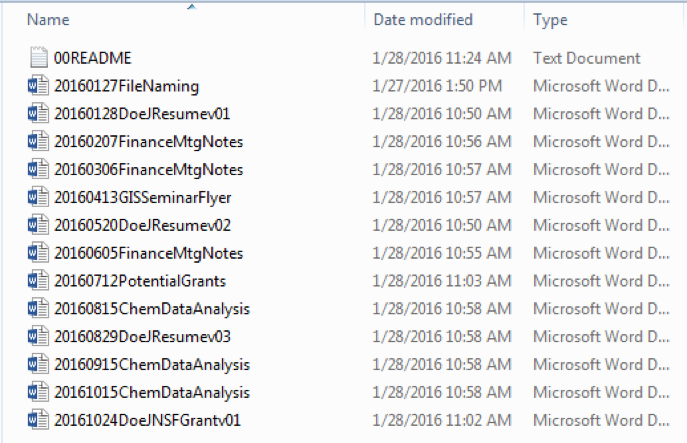
Here again there is no spacing, but the first letter of each word item is capitalized to help distinguish them visually.
A combination: Pick and choose what works for you. All of the earlier examples use a method sometimes found to be most visually clear, which involves a mix of spacing dates with dashes, concepts with underscores, and using camel case.
Again, for your reference:
Here the date is spaced with dashes, underscores separating concepts (the date, the file name, and the version number), and camel case helps keep the words visually distinct.
The most important thing about your file naming convention is that it is understandable and practical for everyone in your organization. If people don't understand a naming convention, or find it impractical, they are much less likely to use it. File naming conventions are only useful when they are used consistently.
Thinking About Data
Below are seven questions that frame how researchers can productively think about data as they prepare a data management plan, collect, analyze, and store data, and compile the associated metadata. Some questions are fairly straightforward, while others have multiple nested components. Ideally, researchers can leverage this information to streamline their data management process from start to finish.
Who?
This question considers who takes credit for the data, which can include researchers who worked on data collection and sponsors who may have supported it. When thinking about this component of data, consider who was responsible for asking the questions that prompted the data, who takes responsibility for the data, and what their role was in the data collection. This can range from the PI on a project to undergraduate researchers who assist data collection, to external analysts brought in on a project.
Consider who should be a point of contact for the data, often who would be most appropriate to explain the data or collection processes. Also think about who will be responsible for maintaining or distributing the data. Depending on the metadata standard you are using, some or all of this information may need to be recorded.
What?
This question asks what the data is. For example, what has been measured, recorded, observed, calculated, or assessed? This question also covers units of measurement, feet or miles, inches of rainfall or whether or not the data is aggregated, as in sums or averages.
Where?
three different components of location. First, where was the data collected? This can be a field site, lab, or off-site research facility. Second, where was the data processed? This is most commonly a lab or an office. Third, what is the geographic coverage of the data? For instance, if data is providing information about rainfall, what is the coverage area? What datum or coordinate system is the data presented on? What method was used to geolocate the data?
When?
This question asks about temporal concerns of the data. Consider whether it is necessary to include the date or time the data was collected, or to indicate the date or time range of the data itself. For example, a lab test that was run at 9:00am, Wednesday, October 19th, or rainfall data collected daily between January 2015 and January 2016. This content should be structured, consistent, and indicate which time zone is being used, if applicable.
Why?
This question prompts researchers to think through why their data has been collected. Is the purpose of the data general information? Is it designed for a specific application, like mapping or input into a particular model? What are the known limitations of the data? Are there known gaps? People who are unfamiliar with the data should be able know why it was collected, how it is intended to be used, and whether it has any limitations they should be aware of.
How?
Here researchers should think about how their data was collected. What instruments were used in data collection and processing? If there were multiple instruments, or varieties, that should be noted. If the instrument used changed midway through the process, make sure that is clear. Were any sensors used? Surveying equipment? What algorithms were used to process the data? Researchers should note any models or software that they used during the processing and analysis of the data. It is very important that researchers keep track of their methods from the start of a project through to the end. This will enable future researchers to more effectively replicate results or build off prior findings.
Access?
This last question is about accessing the data. Researchers should be aware of and make clear the licensing terms of their data. Some organizations have specific licenses for their data, so if researchers use that data, the applicable licenses should be clearly stated in the metadata. If the data is going under embargo, researchers may want to indicate why, and when it should be expected to come out of embargo. If there are any limitations, either from the researcher or institution on redistribution or modification of the data, these should be clearly articulated. If there are any privacy concerns relating to the data, researchers should make sure that appropriate precautions are taken, and that these concerns are clearly understood.